异步的Warshall算法找了半天没找到参考,自记一篇
同步算法
同步的Floyd-Warshall算法还是很简单的,算法过程如下
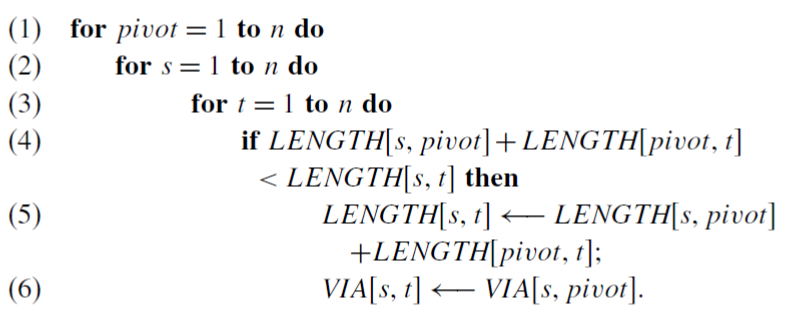
也很好理解,就是对于每条路径 (s->t),寻找他们经过的最近的那个中间点(pivot),目标是找到一个s->pivot->t的路径比当前确定的s->t的路径还要近。所以就不停的测试,从s到t的路径变成s->1->t,s->2->t……会不会近一点……
更深入来说,其实是一种动态规划的思想,先找到任意两个节点通过节点1的最短长度,然后再找通过节点2的最短长度=min{using 1, 2}
可以去百度一下,同步算法的博客有很多,讲的比我详细的多,直接搜floyd-warshall就可以了
异步算法
异步算法就比较奇怪了,首先我们使用同步算法的依据是LENGTH这个变量保存了所有的距离信息,也就是说,全局的距离信息都是已知的,然而到了异步版本,每个进程都只知道自己到各个节点的距离(标记为LEN,而且这个最近的一跳也要记下来,标记为PARENT),而不知道其他两个节点的距离,所以我们需要处理,让每个进程知道全部的消息。
还是要按照同步算法的思想来处理,所以循环的最中心最重要的变量是pivot到各个节点的距离,所以我们可以将pivot节点的LEN信息对全网进行广播,所以其他节点就可以根据此个pivot的信息对自己的变量进行更新了。

草草的总结了一下,大致是这个意思的
依次用每个节点作为中心点pivot
- 对于每个邻居节点nbh
- 如果当前节点到pivot的最短路的下一跳是nbh,那么给nbh发送一个
intree(pivot) - 如果不是,那给nbh发送一个
notintree(pivot)
- 如果当前节点到pivot的最短路的下一跳是nbh,那么给nbh发送一个
- 等待每个邻居节点nbh的
intree和notintree消息
如果当前节点和
pivot已经找到了路径,那么- 如果pivot不是自己,就从到pivot的下一跳节点请求
PIVOT_ROW - 对每个nbh邻居节点
- 如果收到了nbh的
INTREE消息- 如果pivot是自己,给nbh发送自己的len
- 如果不是,就发送自己存的
PIVOT_ROW给nbh
- 如果收到了nbh的
- 当前就知道了自己到pivot的距离,pivot到其他节点的距离,可以更新路径
- 如果pivot不是自己,就从到pivot的下一跳节点请求
- 对于每个邻居节点nbh
解释
还是集中式的算法一样,用每个节点作为pivot进行考虑,程序开始时,所有节点都给自己的邻居节点发送INTREE和NOTINTREE消息,表明自己想要到达pivot节点,需要(或不需要)下一跳经过这个邻居节点。
然后每个节点都进入了await状态,直到收到各自的所有邻居节点发来的消息。
然后程序继续执行
如果LEN[pivot]不是无穷,也就是当前节点已经找到了和pivot相连的一条路径
如果没找到的话,那么说明当前节点和pivot不相连,也就没有更新路径的可能性了,在当前pivot阶段,程序可以结束了,等待下一次循环
继续进行判断,如果pivot是自己,那么自己的LEN就是pivot_row这个变量。如果不是呢,那么就要想办法获取这个变量(pivot节点到各个节点的最短距离),所以从离pivot更近的一个节点进行寻找,也就是说从Parent[pivot]进行寻找,等待它给我们发送一个pivot_row的信息。这里又要进入await状态了,没有这个消息我们确实寸步难行。
得到之后,我们遍历每个邻居节点nbh。如果收到了nbh的intree消息,那么说明我们当前节点是nbh到pivot节点的下一跳,也意味着我们要给它发送pivot_row消息(对照上一段),所以我们给他发pivot_row,同样,如果自己就是pivot,那就发自己的len就可以了,如果自己不是,那就发自己收到的pivot_row(上一段收到的)。
这样操作结束后,当前节点通知了所有其他需要通知的节点PIVOT_ROW消息,所以理论上来说,让所有节点都收到pivot_row消息的操作已经圆满了(至少分配给自己节点的任务已经完成了),可能需要等一等,就可以让所有节点知道合理的pivot_row了。
当然我们的当前节点没有必要等待,它可以直接进行下一步了,那就是更新自己的LEN变量(根据pivot_row和len,就相当于同步算法的length[s, t]和length[pivot, ...])
这样,就可以让所有节点生成一棵全源最短路的图了。
总结
本质上来说,这个和集中式的算法没有区别,但是为了不同进程的同步,我们加入了很多处理同步的内容,需要耐心但不是特别难。

